CLIP Text Encode (Prompt) node is an important node for converting text into conditionings, which can provide guidance for image generation based on any text prompts.
Introduction
This node can be used to encode a text prompt using a CLIP model into an embedding that can be used to guide the diffusion model towards generating specific images.
It focuses on converting text prompts into a structured format (conditioning) that captures the essence of the input for use in conditioned generative tasks, making them suitable for further processing or integration.
Inputs
| Name | Explanation |
|---|---|
CLIP |
The CLIP model used for encoding the text. |
text |
The text to be encoded. |
text
The node includes a text box for entering text prompts. Detailed descriptions can refine the generated image to better match your expectations. Multiple descriptions can be input, separated by commas, for a more precise outcome.
| Prompts | Result |
|---|---|
| Vincent Van Gogh |  |
| Vincent Van Gogh, impressionist painting, oil painting, portrait painting |
 |
| Vincent Van Gogh, impressionist painting, oil painting, portrait painting, layered thick coating pigment technique, intense color contrast, clear strokes with distinct lines, strong contrast between light and dark, chaos background with stars, deep gaze, deep anxiety and sorrow |
 |
The table above illustrates how to craft effective text prompts for image generation. It’s recommended to specify aspects such as style and medium, reference specific artists or works, outline themes and content, and detail any desired visual effects.
What’s more, you can use “:” and a number between 0~1 to determined the weight of each prompt.
(Vincent Van Gogh:0.2), (impressionist painting:0.7), (sunflower:0.5)
Outputs
| Name | Explanation |
|---|---|
conditioning |
It contains the embedded text used to guide the diffusion model. |
How to Use
Positive & Negative Encoder
For more accurate image generation, two CLIP Text Encode (Prompt) nodes are often used to constrain image generation from both positive and negative directions. They are typically used in conjunction with the following nodes:
-
Load Checkpoint: This node provides a
CLIPmodel for both CLIP Text Encode (Prompt) nodes. Note that you can also use theCLIPmodel from Load LoRA and other nodes. -
KSampler: This node can generate a new version of the given latent base on the
conditioningprovided.
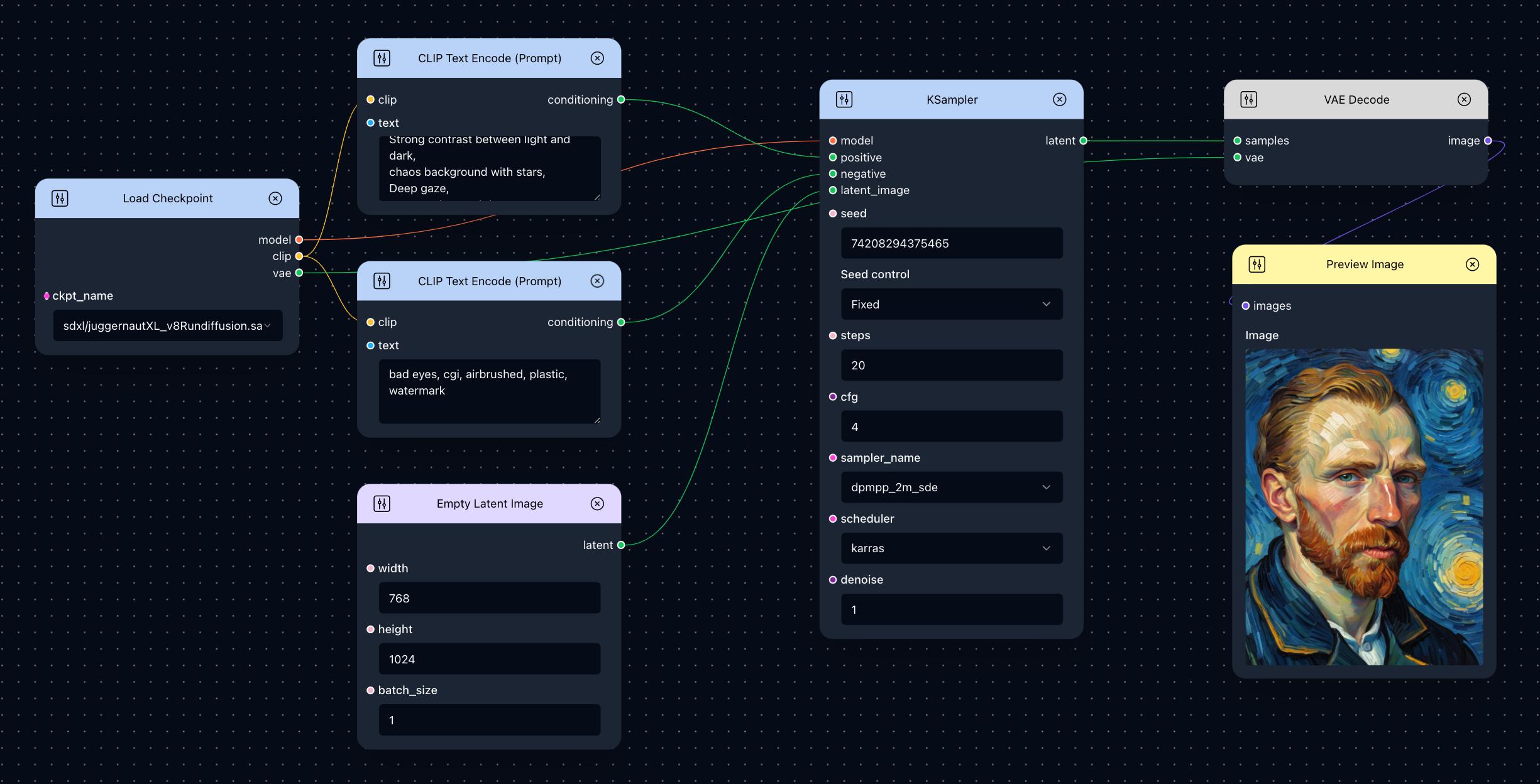
There are two CLIP Text Encode (Prompt) nodes in this simple Text to Image workflow. Tracing the conditioning line reveals one connected to KSampler’s positive input and the other to its negative input, highlighting their differences.
If connected to positive, the conditioning generates positive guidance; correspondingly, the text prompt should describe the desired content and style. Conversely, the unwanted elements can be specified in another node’s text generating negative conditioning.
If you don’t have many requirements for the generated images, you can leave bad text prompt blank. Here, we provide some useful bad text prompts that you can use directly to avoid generating bad images.
bad eyes, cgi, airbrushed, bad quality, watermark, text, low contrast,
extra fingers, fewer digits, extra limbs, extra arms, extra legs, plastic
Conditioning’s Multi-level Processing
It’s important to note that CLIP Text Encode (Prompt) isn’t the only node that can modify conditioning. If you wish to modify it with multiple nodes, the workflow below demonstrates conditioning modified by Apply ControlNet.
You can simply treat the multiple nodes within the red box as a single entity, and their collective function is to add commands that simulate character actions to conditioning. More about Apply ControlNet in here.
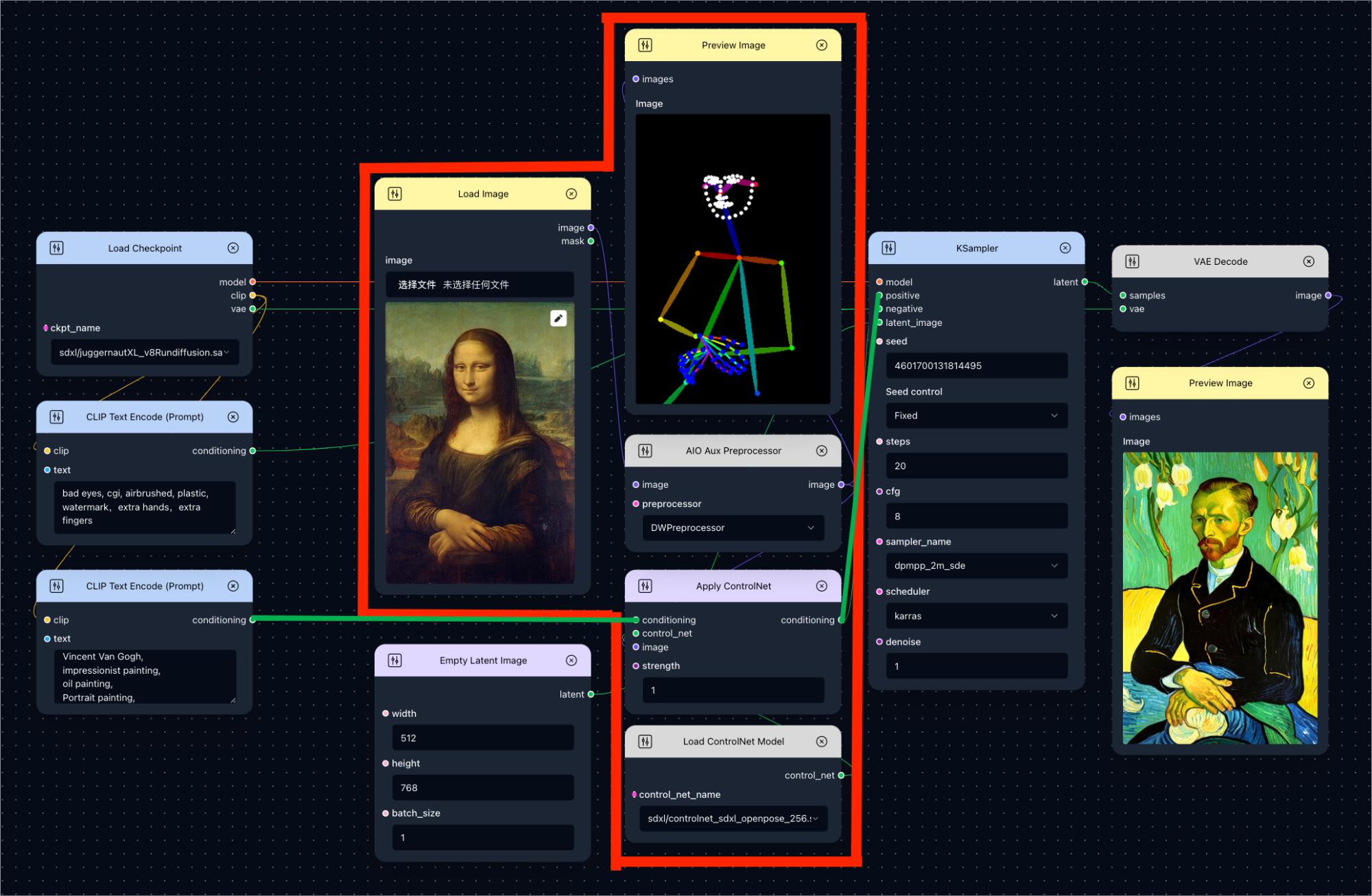
In this workflow, the conditioning generated by CLIP Text Encode (Prompt) aren’t directly sent to KSampler but are processed through Apply Controlnet first, then imported into KSampler (view the bold green line in the image). This node adds new embeddings to the existing conditioning, influencing the final image generation.
This inspirates us that the output of CLIP Text Encode (Prompt) node does not need to be directly connected to KSampler, but can be flexibly used as input of other nodes.